
Quieres que tu página aparezca en muchos (por no decir todos) los sitios. Pero hay partes de tu página web que no son importantes y no quieres que los bots de Google pierdan su tiempo rastreándolas. ¿Cómo se consigue? Evidentemente, con un archivo Robots.txt o meta robots.
¿Por qué?
Porque cuanto más rápido y accesible sea tu página, mejor te posicionará Google y a más sitios relevantes llegarás.
Si quieres saber más sobre Cómo posicionarte en buscadores, lee este post.
¿Cómo se hace eso?
Debido a la cantidad de preguntas que me habéis hecho al respecto, estás en el sitio adecuado.
Como resultado, aquí tienes esta guía paso a paso, donde te mostraré cómo lo puedes configurar, las diferencias y para qué tienes que utilizar uno u otro.
¿Qué es un archivo Robots.txt?

Es un fichero que indica a los bots lo que pueden rastrear y lo que no. Esto no prohíbe que entren en las partes que has indicado como no rastreables, es decir, no vas a ocultarlas porque siguen siendo accesibles.
Sólo le ahorras trabajo a estos bots para que tu página sea más rápida omitiendo ciertas partes innecesarias.
Se bloquea tanto la página como los enlaces que has incluido allí.
¿Cómo funcionan estos bots?

Cuando una persona accede a la Red de Búsqueda (escribe un texto en el motor de búsqueda, por ejemplo en Google), los bots se ponen en funcionamiento.
Lo primero que hacen es entrar en el archivo Robots.txt de las páginas (si existen).
En función de lo que esté establecido en estos archivos toman una decisión u otra de análisis.
Si no tienes un archivo así, puede perjudicarte porque gastarán demasiado tiempo buscando en tu sitio, sobre todo si es una página con mucho contenido, y la clasificarán como de difícil acceso.
Resumen:
En cualquier caso, tener un archivo Robots.txt posicionará mejor tu página web.
Diferencia entre meta robots y archivo robots.txt
- Los meta robots son indicaciones en formato HTML entre las etiquetas head que indican a Google el valor que le tienen que dar a los enlaces. Dependiendo de la instrucción que le des puedes hacer que indexe y rastree, indexe pero no rastree, no indexe pero rastree o no indexe ni rastree.
- En cambio, el archivo Robots.txt bloquea páginas y los enlaces que estén allí para que Google no las rastree, pero sí sean indexadas.
Por lo tanto, son instrucciones y no reglas.
Por esto, lo que te comentaba antes, pueden saltarse este archivo y rastrear tu página, con cualquiera de las dos opciones anteriores.
¿Y eso cuándo pasa?
Cuando varios enlaces apuntan hacia la página que hayas marcado como no rastreable o no indexable dentro del archivo, lo más probable es que Google la indexe, la rastree y la muestre en las SERP porque la categorizará como relevante.
Ventajas
Meta robots:
Cuando Google accede a una página, sigue el camino de los enlaces que hay allí, mientras que con una etiqueta de meta robots evitas que indexe los enlaces que no tienen interés haciendo el trabajo más fácil.
Archivo robots.txt:
Si lo que quieres es bloquear un directorio completo, utilizar un archivo robots.txt es mucho más eficaz. Les ahorras a los bots tener que entrar en la página y ver qué pueden rastrear y qué no, por lo que pueden rastrear mayor número de páginas y más rápido porque obvia directorios completos.
¿Qué comandos puedes dar al archivo robots.txt?

Recuerda que para saber si ya existe un archivo así en tu página solo tienes que escribir robots.txt en el slug, te quedaría tal que así:
anadelmazo.com/robots.txt
Además, si accedes a esta página de Google y haces clic en Abrir la herramienta Probador de Robots.txt te permitirá ver si lo has configurado correctamente y a través de todos los bots de Google.
Reglas:
- Utiliza sólo los comandos permitidos.
- Distingue entre mayúsculas, minúsculas, espacios y signos de puntuación, así que presta atención para escribirlo correctamente.
- Debes dejar una línea en blanco para separar los grupos de comandos de User-agent.
Comandos:
- User-agent: especifica a qué tipo de bots van dirigidos estos comandos. Lista de User-agents.
- Disallow: bloquea el acceso.
- Allow: permite el acceso.
- Sitemap: especifica donde se encuentra el XML sitemap del sitio.
- Crawl-delay: indicas el tiempo de retardo que tiene que esperar el bot para rastrear la siguiente página. No todos los bots hacen caso a este comando.
- /*/: especifica que son todos. Ejemplo: para todos los bots, para todos los directorios…
- $: especifica las extensiones de archivo que hayas indicado. Ejemplo: /* .css$
- #: para poner notas que querramos añadir al archivo. No son comandos, sino que sirven de manera explicativa.
¿Qué comandos puedes dar al meta robots?

Comandos:
- Index, Follow: que indexen y luego rastreen.
- No index, Follow: que no indexen pero que sí rastreen. Sirve para evitar que salga en las SERP.
- Index, No follow: indexa pero no rastrea la página. Sirve para evitar que se siga los enlaces que hay en la página que has especificado.
- No index, No follow: ni indexa ni rastrea.
Cómo configurar el meta robots con Yoast SEO
1. Yoast SEO > Apariencia en el buscador > Tipos de contenidos
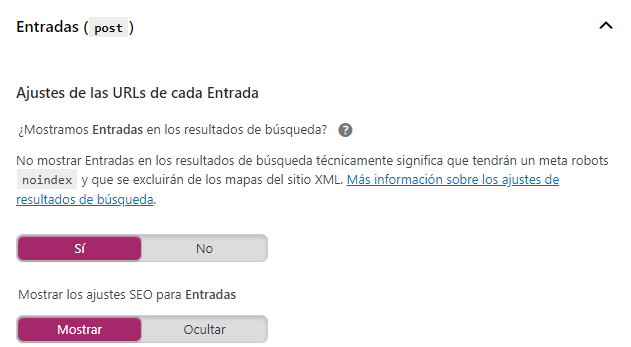
Si cambias la configuración a no tus entradas dejarán de salir en las SERP. Deja marcado el sí para que no exista ningún comando noindex en tus entradas.
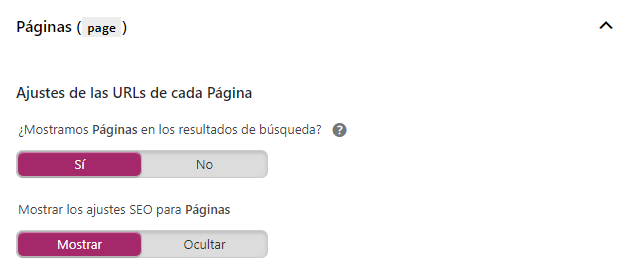
Igualmente pasa con tus páginas:
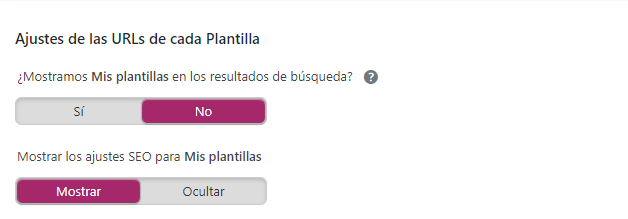
Así como con tus plantillas. Aquí te recomiendo que tengas marcado el no porque es un dato completamente innecesario que las plantillas que estés utilizando salgan en las SERP’s.
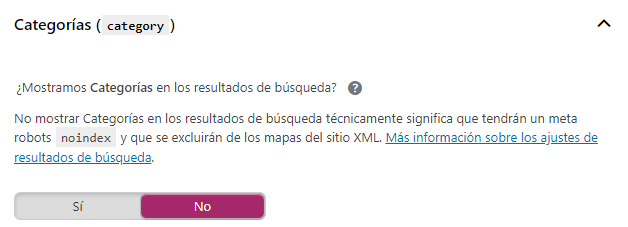
2. Apariencia en el buscador > Taxonomías
Hay que tener mucho cuidado con el contenido duplicado porque Google nos puede penalizar por ello llegando a eliminarnos de los resultados de búsqueda.
Mientras que los bots establecen un tiempo para rastrear una página y todos los enlaces que haya en ellos, si encuentran contenido duplicado el tiempo de rastreo se va a reducir y van a encontrar menos información de valor que mostrar.
También afecta a nuestra estrategia de backlinks y Social Media y van a limitar nuestro rendimiento.
Por lo tanto te recomiendo que en este apartado pongas esta configuración para evitar el contenido duplicado:
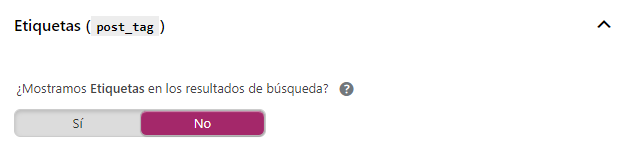
Así como los formatos diferencian los tipos de entradas entre galería, citas, minientradas…
No conviene tampoco tenerlo indexado por lo que lo dejamos en no.
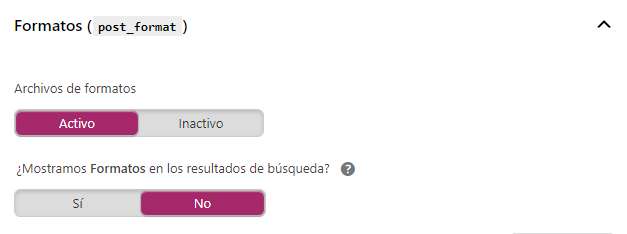
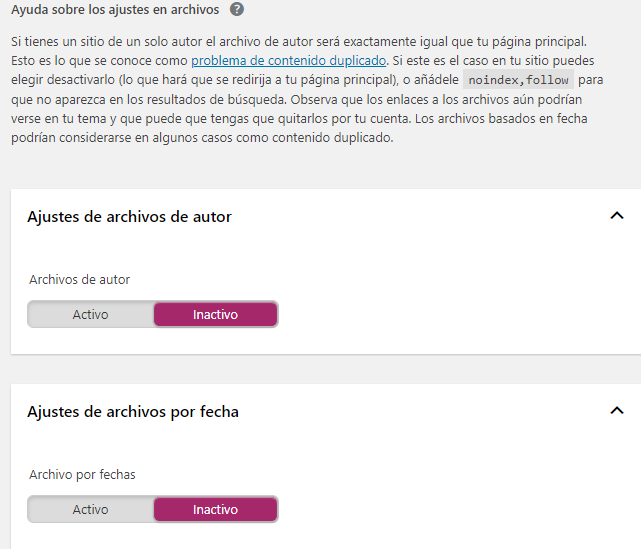
3. Apariencia en el buscador > Archivos
Por otro lado, si tu página cuenta con varios autores que crean entradas, te recomiendo que lo tengas activado.
Por el contrario, si sólo existe un autor deja marcada la opción desactivado.
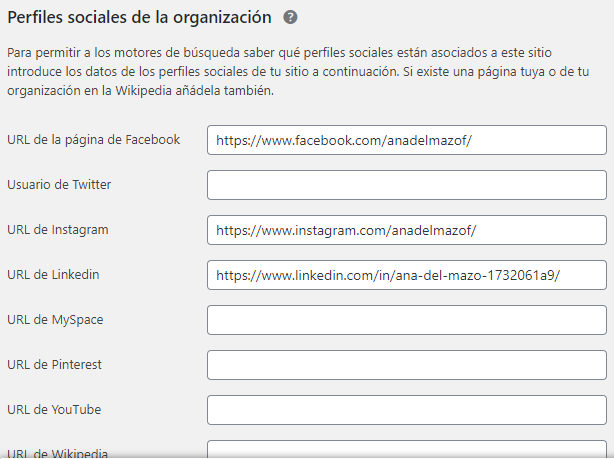
4. Yoast SEO > Social > Cuentas
Sirve para que los bots vinculen tus redes sociales con tu página.
5. Yoast SEO > General > Características
Debes tener esta opción desactivada, si quieres saber más sobre la Configuración de los XML sitemap, lee este post.
Y te digo desactivada porque esta opción no funciona muy bien con este plugin, de hecho, yo utilizo Google XML Sitemap exclusivamente para esta función.
6. Ajustes > Enlaces permanentes (en el menú de la barra lateral izquierda de WordPress).
Asegúrate de tener la opción Nombre de la entrada marcada como en la imagen.
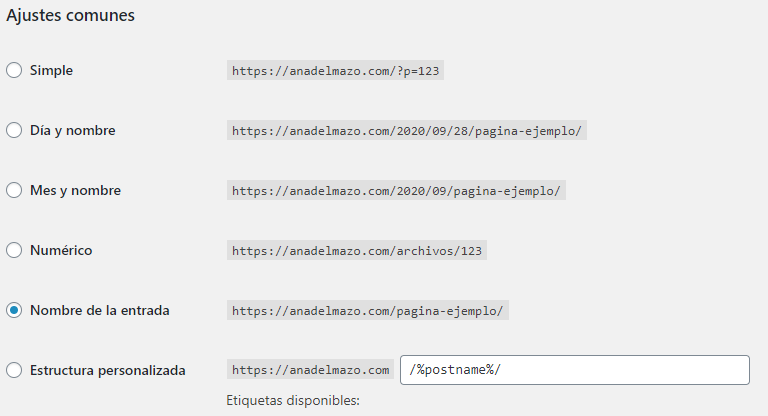
De hecho el propio CMS nos advierte al entrar en esta página sobre la repercusión que tiene elegir una opción u otra para nuestro SEO.

Cómo configurar el archivo robots.txt con Yoast SEO
1. Yoast SEO > Herramientas > Editor de archivos.
Antes que nada, te aparecerá este menú:

2. Clic en Editor de archivos.
Y nos redirige a esta página:
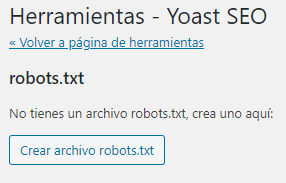
3. Clic en Crear archivo robots.txt.
Por lo que nos cambiará la página en la que estábamos por esta otra:

4. Nuestro archivo robots.txt ya está creado.
Lo siguiente que podemos hacer es meterle los comandos que te he especificado antes para bloquear directorios o páginas.
5. Hace tiempo Google advirtió que bloquear el contenido CSS o JavaScript es perjudicial para el SEO de tu página.
¿Recuerdas el comando $?
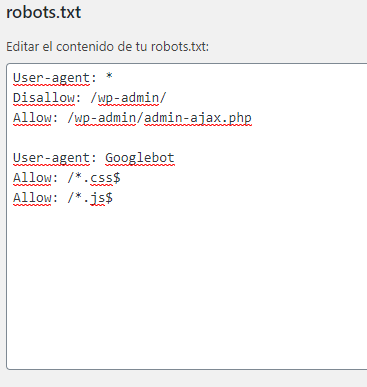
Pues copia y pega este bloque en la cajita de robots.txt creada:
User-agent: Googlebot
Allow: /.css$
Allow: /.js$
Te tendría que quedar tal que así:
6. Evitamos que se rastreen los feed, comentarios, carpetas, etiquetas…
Por lo que se le indica a todos los bots que se permita el acceso al AJAX pero se le deniegue a las partes innecesarias de nuestra web.
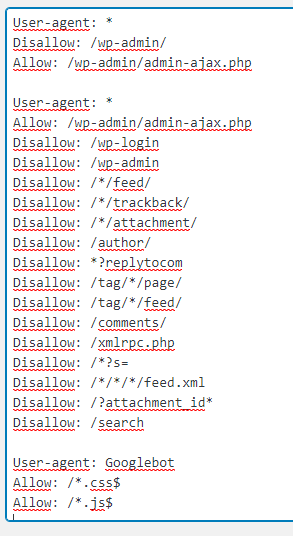
Entonces copia y pega esto:
User-agent: *
Allow: /wp-admin/admin-ajax.php
Disallow: /wp-login
Disallow: /wp-admin
Disallow: //feed/ Disallow: //trackback/
Disallow: /*/attachment/
Disallow: /author/
Disallow: *?replytocom
Disallow: /tag//page/ Disallow: /tag//feed/
Disallow: /comments/
Disallow: /xmlrpc.php
Disallow: /?s= Disallow: ////feed.xml
Disallow: /?attachment_id*
Disallow: /search
Te tiene que quedar tal que así:
7. A veces las páginas de Gracias aparecen en los buscadores cuando no han pasado por ningún proceso de conversión,
Así que es conveniente bloquearla para que Google no la muestre:
Disallow: /gracias/
Noindex:/gracias/
Gracias equivale al slug que le hayas puesto a tus páginas de gracias. Crea tantos comandos disallow + noindex como páginas de gracias tengas para que no aparezcan en las SERP.
8. Por último, le indicamos cuál es nuestro o nuestros XML sitemap, para ello tienes que escribir:
Sitemap: http://www.tudominio.com/sitemap.xml
9. Guardamos los cambios y entramos en nuestro archivo robots.txt (tudominio.com/robots.txt) y ya tendremos el resultado:
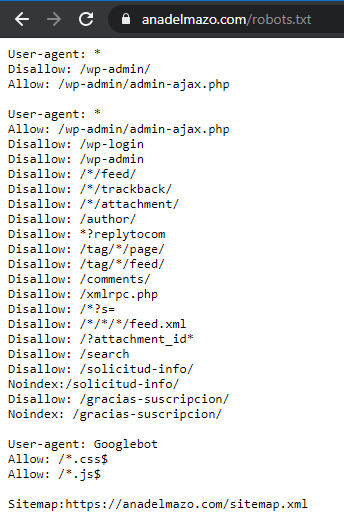
Recuerda que puedes comprobar si funciona correctamente con Google Search Console y que este es sólo uno de los pasos fundamentales en tu estrategia de SEO. Si no sabes cómo Vincular tu dominio con Search Console, visita el anterior enlace.
Te recomiendo que visites el siguiente paso: Investigación de palabras clave.

Finalmente, ¿Qué te ha parecido esta guía? ¿Te ha resultado de utilidad toda la información que te has encontrado aquí?
¡Espero poder seguir ayudándote! Te leo en los comentarios y en las redes.
Tienes muchas más como esta en mi Directorio de Posts y por aquí te dejo mi Carta de Servicios.

sitio de blogs fantástica y excepcional. Realmente deseo agradecer a usted, para que nos proporciona información mucho mejor.
¡Gracias a ti Sallie! ❤️ Un placer poder aportaros información valiosa.
I constantly emailed this blog post page to all my contacts, for
the reason that if like to read it afterward
my friends will too.
I’m not sure where yyou aare getting your info, but
good topic. I needds too spehd somee time leaarning more or understanding more.
Thanks for excellentt informtion I wwas lookingg foor tyis information.
Everything is very open with a clear explanation of the challenges.
It was really informative. Your site is very
useful. Many thanks for sharing!